Web Scraping with Firebase
Build your own Price Tracker with Puppeteer and Firebase Cloud Functions


Table of contents

No headings in the article.
What is web scraping?
It is the process of extracting information and data from a website, transforming the information on a webpage into structured data for further analysis. Web scraping is also known as web harvesting or web data extraction. With the overwhelming data available on the internet, web scraping has become the essential approach to aggregating Big Data sets.
In a nutshell, web scraping is the process of extracting data from websites. All the job is carried out by a piece of code which is called a “scraper”. First, it sends a “GET” query to a specific website. Then, it parses an HTML document based on the received result. After it’s done, the scraper searches for the data you need within the document, and, finally, converts it into the specified format.
In this post we will be building a amazon price tracker that will track the price of any product. We will be using puppeteer to scrap the price of product from amazon website and the prices can be stored in the database, so that we have history for the price of any product.
We will be using firebase cloud functions to run this applications. For this you need to enable billing for your firebase project. We will stored the prices captured in the firestore.
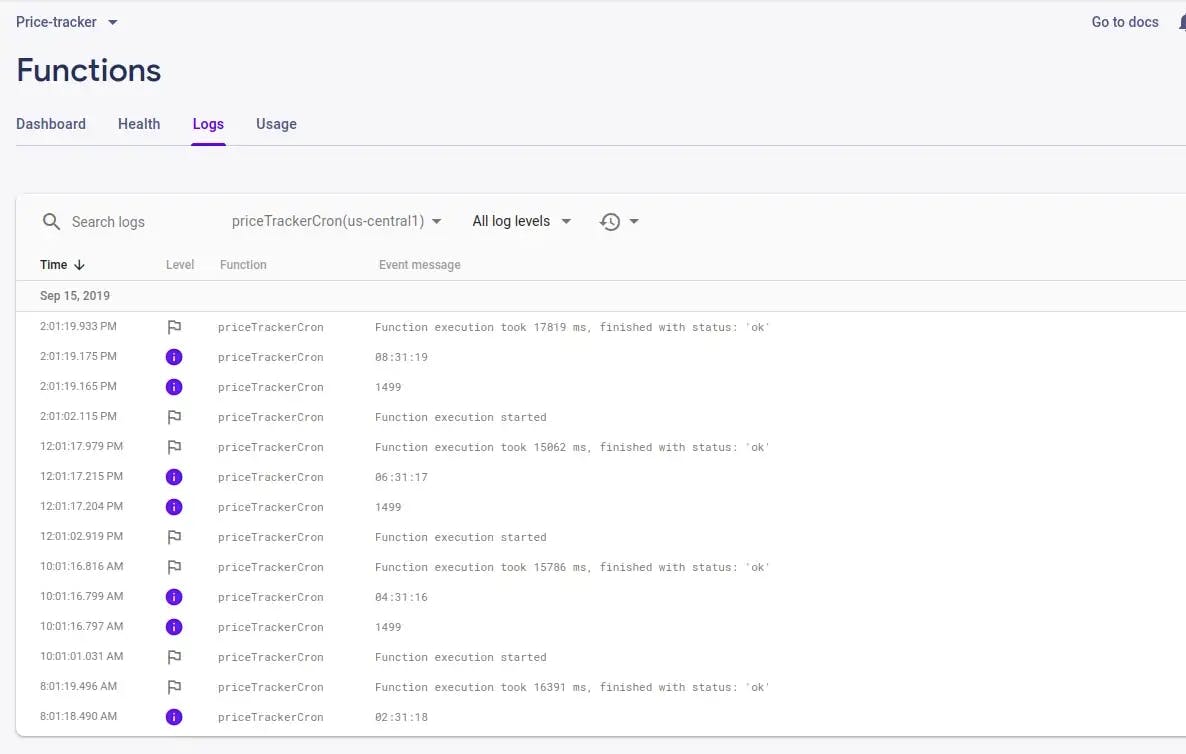
Here i am using the cron job function in firebase to run the price tracker every 120 minutes. So the price will be stored will in every 120 minutes in the firetore.
In the function priceTrackerCron we are passing options to runWith() function since puppeteer requires a lot of memory to run also we have set up the timeout to 300 seconds so that there is no timeout in function execution.
In the findPrice() function you can see that we have passed args (arguments) in the launch function of puppeteer args: [‘ — no-sandbox’, ‘ — disable-setuid-sandbox’] these arguments allow us to run the puppeteer in the container created for us by the firebase to run the headless chrome(since you cannot run chrome as a root user).
At line 16, we are enabling the interceptor and blocking the images, fonts and css stylesheets to load, this will drastically reduces the loading time of the web page in puppeteer.
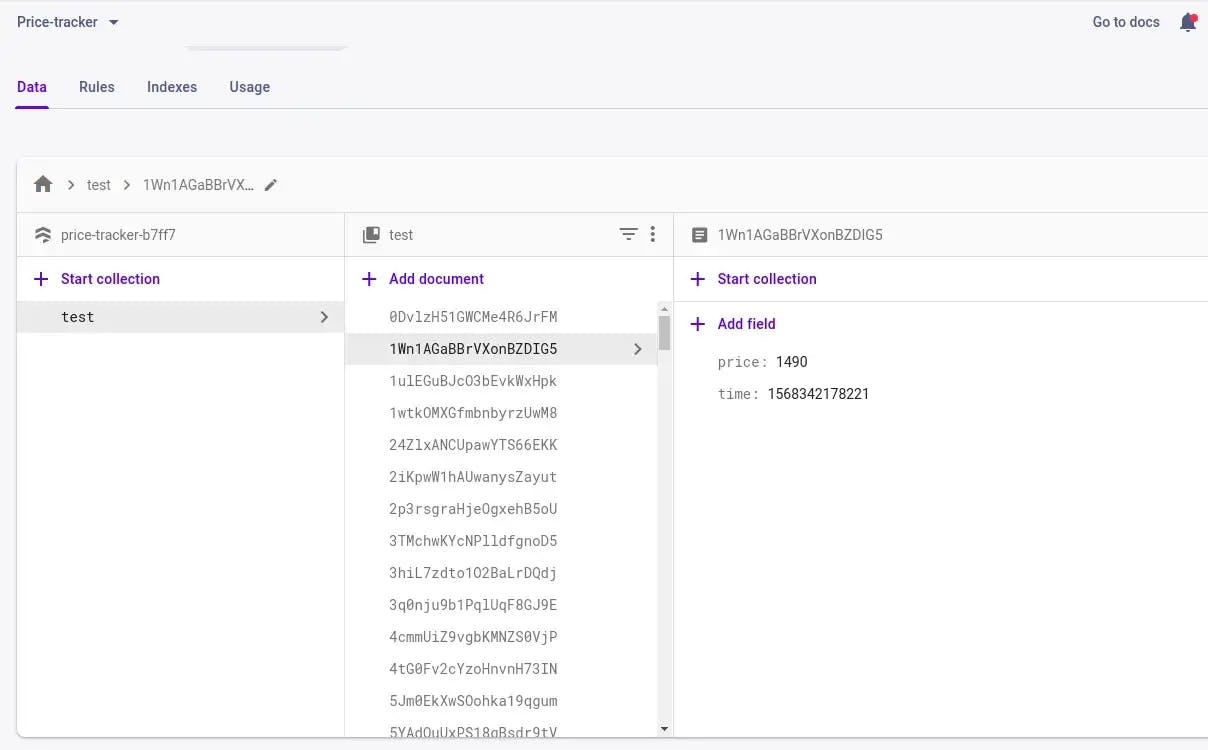
In the page.evaluate() function at line 28, we are capturing the price of the product price document.querySelector(‘#priceblock_ourprice’).innerText and converting it to number and storing in the firestore.